Reception and impacts
A look back on the blog and some of its impacts.
Earlier this month, my post on page dewarping was featured on Episode 207 of the Real Python Podcast. It was really cool to hear the hosts Christopher Bailey and Christopher Trudeau discuss my writing style and characterize my approach to problem-solving. It was also especially gratifying to realize that a blog post that I wrote in 2016 – practically ancient history in the coding world – is still resonating with people and generating novel conversation today in 2024.
Like this latest podcast mention, every so often I learn about the blog getting external recognition, and I decided it was past time to explore its impacts more systematically.
Pageviews and traffic sources
I’ve used Google Analytics to track site traffic from the start of the blog in summer 2016 until summer 2023 when that version of Google Analytics reached end-of-life. Over that 9-year period, Needlessly Complex received 380,296 unique pageviews!
Here’s a top ten list of posts on the site, ordered by unique pageviews:
| Rank | Page | Unique pageviews |
|---|---|---|
| 1 | Compressing and enhancing hand-written notes | 144,168 |
| 2 | Page dewarping | 74,950 |
| 3 | A minimal ray tracer | 36,855 |
| 4 | Flow Free solver | 26,252 |
| 5 | Unprojecting text with ellipses | 12,273 |
| 6 | Watertight vector maps from raster images | 9,391 |
| 7 | SymPy case studies, part 2: derivatives | 7,549 |
| 8 | Ukulele tuner | 5,867 |
| 9 | Flow Free redux: eating SAT-flavored crow | 3,974 |
| 10 | Gabor^2 | 3,534 |
For what it’s worth, if considered as a post, the “about me” page would fall at #8 on the list above, with 7,099 unique pageviews.
I never decided to update to the new and improved Google Analytics 4, so I don’t think I’ll be counting pageviews like this in the future, but it was certainly interesting to be able to watch the counter tick upwards after someone linked to one of my posts from Hacker News, Twitter, or Facebook.
Hacker News
Many of the pageviews the blog has received originate from Hacker News (HN), a social link aggregator created by Paul Graham. HN users can submit links which are shown on the front page and sorted by a combination of recency and “points” which reflect user voting, with more points denoting higher popularity. Links posted on HN normally tend to range from 10 to 1,000 points. Users can also comment on each link, although the commentary often ends up being highly tangential to the originally-posted link.
The first big hits I got from HN were from two links posted by other users on August 18, 2016. On that date, my page dewarping and minimal ray tracer posts were both featured, and ended up being the #2 and #4-ranked links from that date on the site, scoring 743 points and 395 points respectively, and with conversations generating 70 comments and 61 comments, respectively, as shown here:
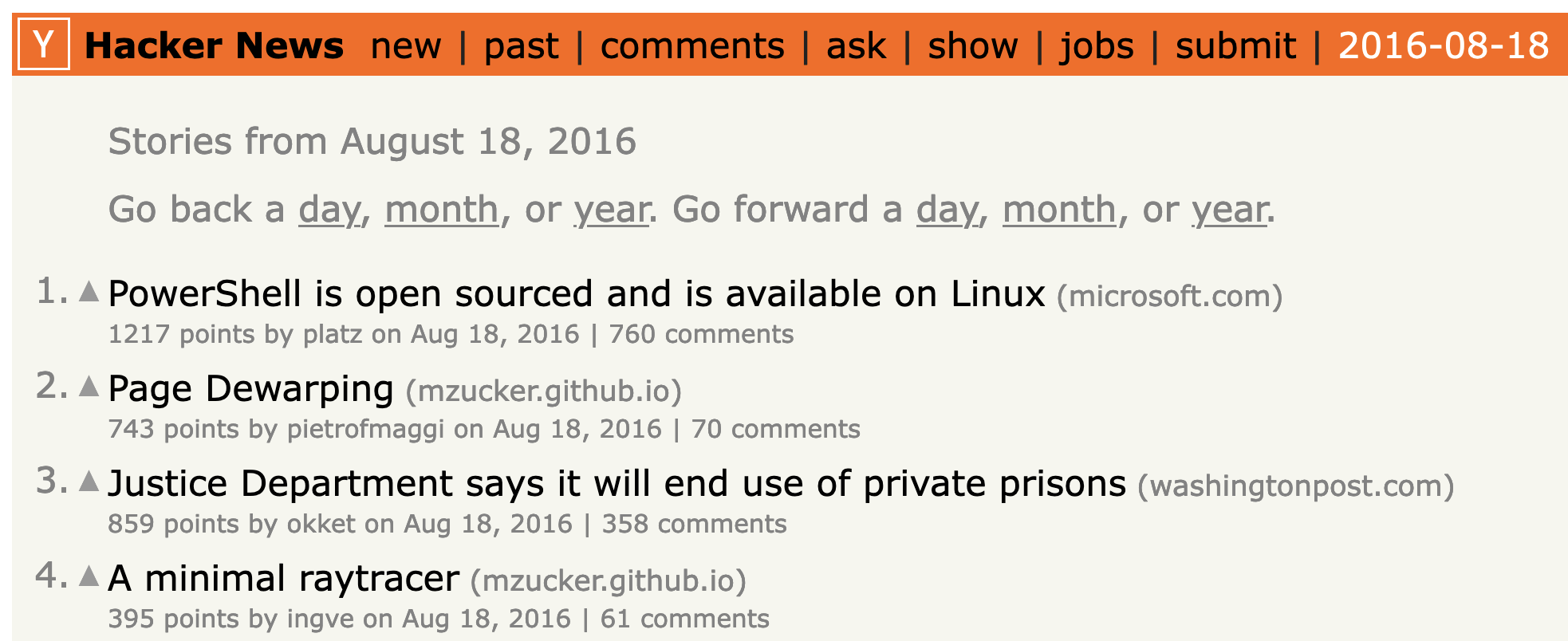
Those posts are the largest engagement I’ve seen from HN, but there’s been a steady trickle of traffic since then. Also, since HN allows multiple postings of a given URL and reposts get their own scores and comments, I’m still getting new traffic from HN from older articles. For example, last month two HN users posted links to my page dewarping and unprojecting text articles, garnering scores of 205 and 151 points respectively – again, not bad for content from 2016!
Some of my projects got posted to reddit.com, another popular large-scale social link aggregation site. There are many so-called “subreddits” set up to focus on particular topics and interests, and one of the more heavily trafficked subreddits for coding is /r/programming.
My noteshrink project was posted to /r/programming in March 2018 and the user comments indicate positive engagement with my work. Here are a few choice quotes:
Realistic problem? Check. Explained every step of the way? Check. Bonus explanations for relevant material? Check. Useful images? Check. Wonderfully done.
This is what every half-assed Medium post wishes it could be.
As an aspiring Python developer, this is extremely impressive. It boggles my mind how powerful (and how many applications) the language has.
Previously in August 2016, noteshrink was featured on /r/programming, which also elicited some positive feedback:
It’s not often I get to say this here, but this is pretty f*cking cool. It makes sense, the results are solid and it immediately seems useful.
The cool part is how well it seems to be working. The final result looks as if you took the page and pushed it down flat on a scanner.
It’s great to see my work resonating with readers on other sites!
Open-source code
All of the code featured in my blog posts is hosted on github.com. The majority is distributed according to the highly permissive MIT license, which makes it easy for people to incorporate the code into their own projects. The combination of Github hosting and a permissive license creates opportunities for broad exposure and impact.
Github engagement
Github allows users to “star” (i.e. “favorite”) repositories. Similar to favorites on social media, stars can be used to indicate appreciation, and to bookmark a repository to track its progress and find it easily later on. Github also allows users to easily “fork” repositories, creating their own copies to which they can add individualized changes and improvements.
The repositories associated with my Needlessly Complex posts have been reasonably popular on github, garnering a respectable number of stars and forks. Here are the top five, sorted by engagement as of publication time:
| Rank | Repository | Stars | Forks |
|---|---|---|---|
| 1 | noteshrink | 4,785 | 351 |
| 2 | page_dewarp | 1,411 | 240 |
| 3 | miniray | 171 | 13 |
| 4 | unproject_text | 144 | 30 |
| 5 | maptrace | 123 | 24 |
Forks, ports, and packages
I don’t spend a lot of time maintaining my code after I finish writing about it, but the magic of Github and open-source is that others are free to do so. Furthermore, volunteer software maintainers are also free to package up my code to be easily installed and deployed on various platforms such as Linux distributions or Python package managers.
Here are some notable forks, enhancements, and packages:
-
Lewis Maddox maintains a port of page_dewarp that updates it to Python 3 (original was for Python 2.7), with active commits up through April 2023. Maddox also has a thoughtful write-up about his porting efforts on his own web site.
-
Tudor M. Pristavu created a Qt-based graphical user interface for noteshrink with app images for easy deployment on Linux. The project had active commits up through June 2023.
-
The Image Processing For Electronic Publications organization has ported noteshrink to C for increased performance. Last commit was in May 2023.
-
There are user-maintained distributions of noteshrink for Arch Linux and Ubuntu.
-
A 2018 noteshrink port by Andrew Challis is available through PyPI.
I’m really glad to see the sustained interest and investment in these software packages – it’s great to see others using and improving my code!
Citations in industry and academia
Despite the fact that it’s not a peer-reviewed academic publication, Needlessly Complex has been cited numerous times by inventors and scholars.
Patent
My page dewarping work forms much of the basis for US Patent 11145037, “Book scanning using machine-trained model”, invented by Moogung Kim, Kunwoo Park, Eunsung Han, and Sedong Nam, and assigned to VoyagerX, Inc. Their patent application citing my post was submitted and approved in 2021. Here is the abstract:
This application discloses a technology for flattening a photographed page of a book and straightening texts therein. The technology uses one or more mathematical models to represent a curved shape of the photographed page with certain parameters. The technology also uses one or more photographic image processing techniques to dewarp the photographed page using the parameters of the curved shape. The technology uses one or more additional parameters that represent certain features of the photographed page to dewarp the photographed page.
Basically it looks like they took my post as a starting point, and added a CNN to tackle some of the dewarping computation. Whem I say my work forms much of the basis of their patent, I’m not kidding – their Figure 5 is captioned as “a Bezier curve model representing a curvature of an opened book page according to an implementation.” Compare this figure from the patent…
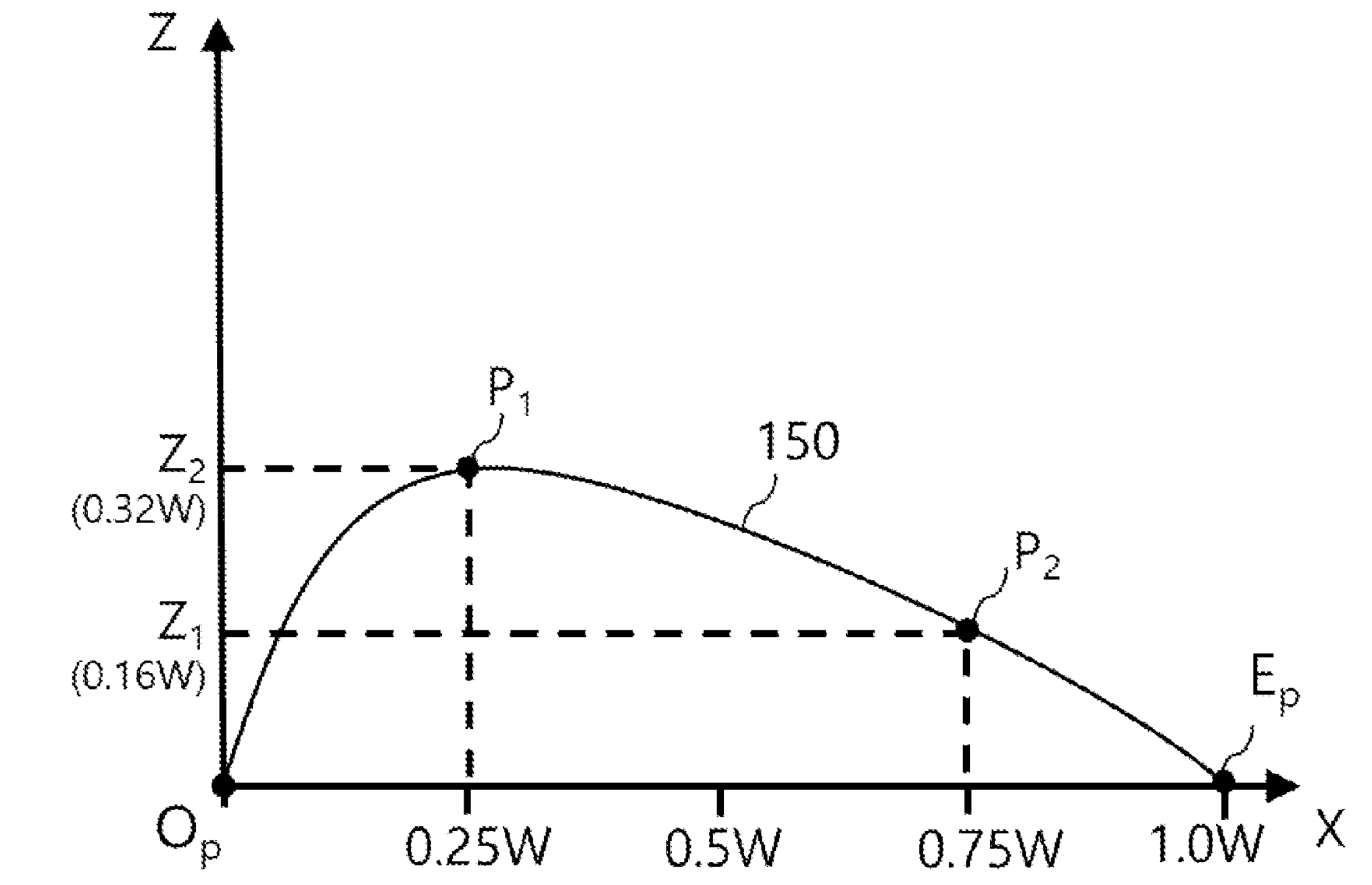
Figure 5 from patent 11145037, “Book scanning using machine-trained model”
…to the blue trace on my original plot of the same idea:
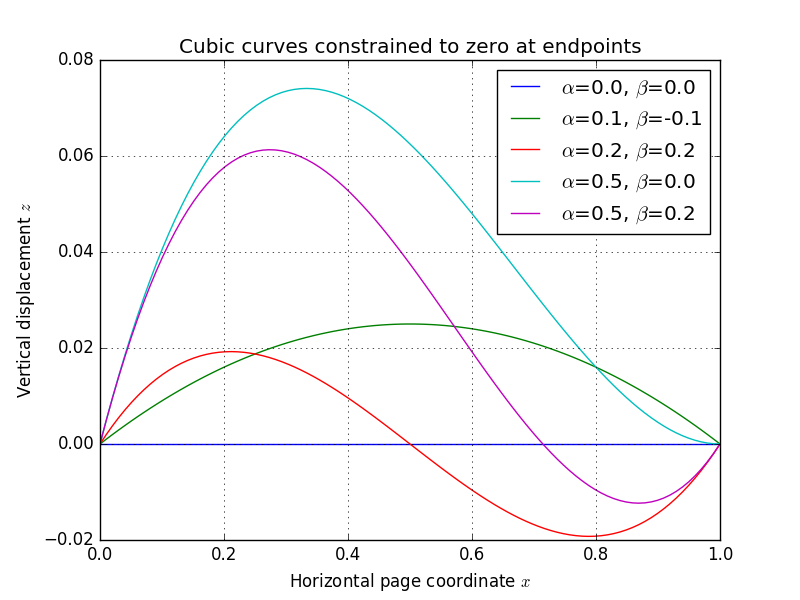
Original plot from my page dewarping post (compare top curve to above figure)
I guess imitation is the sincerest form of flattery?
Theses
A 2018 PhD Thesis by Ahmad Widari from Gadjah Mada University in Yogyakarta, Indonesia entitled Implementation of Page Dewarping on Text Images using the Pixel Insertion Method (Google translation) appears to be an alternative implementation of my page dewarping algorithm, and cites it prominently. Although the publication is not open-access, there is an English translation of the abstract:
This research is focused on developing an alternative device to scanner by using Page Dewarping algorithm. There are many Page Dewarping algorithm that already developed, one of them is algorithm developed by Matt Zucker (2015). Image capturing process is taken with the book is faced up and the camera from above will take the image thus saved into computer. From that saved image, it will be dewarped by Page Dewarping algorithm. First, that image will have its contrast enhanced with CLAHE and binarized by using Otsu Method. Thus there are two different methods to dewarp the image, by using Regression and using Spacing Classification with Modified Binary Search to classify. The program is written in C++ and uses OpenCV library for optimization. At last, this research will compare the result after dewarped and execution time for these two methods. This research’s result shows that these methods have faster execution time than execution time of Matt Zucker (2015)’s method. However, the final result on both methods are worse than the result on Matt Zucker (2015)’s method.
The 2021 Master’s thesis of Libor Machálek from Palacký University Olomouc in the Czech Republic entitled Neural Networks and Automatic Processing of Scanned Documents also heavily cites my page dewarping work, and even goes as far as reproducing the example inputs and outputs from my post:


Finally, Lund University student Jakub Olejnik’s 2023 Master’s thesis entitled Exploration of Alternative Image Representation Using Signed Distance Functions, cited my 2016 Gabor^2 post. As in my work, Olejnik is attempting to reconstruct or approximate images using function approximation – but in his case using transparent 2D shapes such as circles, triangles, and rectangles instead of Gabor functions. Here’s an excerpt of a figure from his thesis…
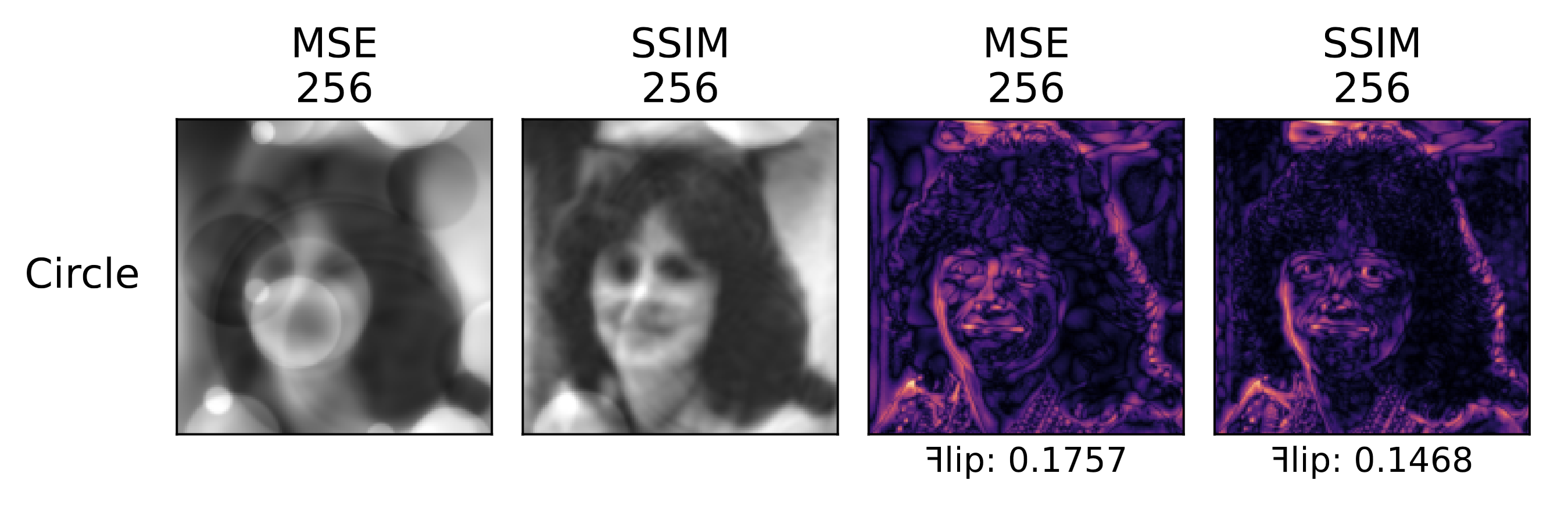
…compared with a comparable reconstruction and error image from my work:

Hopefully the influence is evident!
Nerd-sniping and Flow Free solvers
Comic creator Randall Munroe gifted the world with the concept of “nerd sniping” when he created this comic in December 2007:
The fundamental idea of nerd sniping is that some people, when presented with a sufficiently intruiguing intellectual problem, can think of nothing else besides solving it – even despite the risk of life and limb. It seems my post on solving the Flow Free puzzle game and its SAT-solver-based follow-up had that effect on at least a couple of people, who wrote up their own puzzle solvers inspired by mine.
In 2019, Samuel T. Goldman wrote up an exploratory blog post on his efforts to write a Flow puzzle solver, first in Python, and later in Rust for increased performance. He mentions my work as being helpful for reducing branching factor and heuristically scoring candidate expansions during search.
Subsequently in 2020, Kabalan Gaspard wrote a deep-dive medium post on solving Flow Free with machine learning techniques. Unlike Goldman, Gaspard departs further from the brute-force search/constraint satisfaction domains to look at using Q-learning approaches as well as Convolutional Neural Networks to solve puzzles. I enjoyed corresponding with Gaspard when he reached out to me in the process of completing write-up.
In some ways, these posts are some of my favorite evidence of the impact of Needlessly Complex. Not only did the authors enjoy my own work, but they enjoyed it so much that they were compelled to write their own software and longform pieces describing their efforts. As an academic, I find few things quite as satisfying as intellectual reproduction. Folks citing me or using my code is great, but it feels even more amazing to inspire people to engage in the same kinds of exploration and communication about mathematical coding and problem solving that I enjoy so much.
Conclusions
Overall, my site has received far more traffic than I would have imagined when I launched it. More importantly, it’s earned me a larger and much more engaged readership than I would have had if I had stuck exclusively to peer-reviewed academic publictions.
I want to wrap up this post with a couple of quotes from the Real Python Podcast episode I mentioned at the outset, wherein the cohosts are discussing my page dewarping post:
This for me is a very interesting read about process, of how to solve a problem – which is a part of programming – and so it’s really kind of fun to watch this person go through all the different steps.
One of the things I like about this article is most content on the web about programming is step-by-step tutorials and yeah, that has its place… but that’s sort of like first year kind of education stuff… Very little articles are written about like the idea of how to decompose a problem and and most of us I think we get to it through trial and error over time in our careers, but to actually watch somebody go “okay well, I tried this and this worked and this didn’t work and this is why I tried this next” – I think there’s a base educational value in trying to see how that works.
These quotes really capture the essence of what I’ve been trying to do with this blog over the years: to show coding – especially mathematical coding that reflects the physical world – as a problem-solving process with plenty of room for creativity and exploration. Indeed, I find myself bringing blog posts into my classes from time to time to show my Engineering and CS students the possibilities of what they can accomplish once they are ready to go beyond the fundamentals of just learning to code.
I’m proud that the articles and code I’ve written over the years have proven to be of interest to a wide audience, both from a popular science/educational standpoint, as well as providing useful functionality for people to use for their own personal projects and professional work.
And I look forward to posting more coding-based articles in the future, and to seeing how the blog continues to impact its readers in years to come.